GitHub 项目基础知识
在开始这个项目之前,你需要了解一些关于 GitHub 和 AI 项目的基础知识。这些知识会帮助你更好地理解和使用开源项目。
什么是 GitHub?
GitHub 是全球最大的代码托管平台,开发者在这里分享开源项目。AI 领域的大部分先进工具和模型都通过 GitHub 开源,任何人都可以免费使用和学习。当你看到一个有趣的项目时,你可以通过 clone(克隆)命令将整个项目下载到本地。
项目中的关键文件
README.md 是项目的说明书,里面包含项目介绍、安装方法、使用教程和常见问题解答。使用项目前一定要先读 README!
requirements.txt 列出了所有需要安装的 Python 包和版本号。通过 pip install -r requirements.txt 可以一键安装所有依赖,避免版本冲突问题。
config.json 或 config.yaml 是配置文件,定义了模型架构、训练参数、推理设置等。修改这些文件可以调整模型行为,无需改动代码。
模型权重文件
AI 项目的核心是模型权重文件,通常为 .pth、.pt、.bin、.safetensors 等格式。这些是训练好的模型参数,文件很大(几 GB 到几十 GB),通常不直接放在 GitHub 上,而是通过 Hugging Face 等平台单独下载。
Stars 和项目质量
GitHub 上的 Stars 数量反映了项目的受欢迎程度和维护质量。高 Stars 的项目通常意味着:更稳定、社区活跃、文档完善、问题更容易找到解决方案。当你不确定选择哪个项目时,优先选择 Stars 较多的项目。
Hugging Face 平台介绍
Hugging Face 是 AI 领域的"GitHub",专注于机器学习模型和数据集的托管。在这个项目中,我们会用到 Hugging Face 来下载 CLIP 模型。
Hugging Face 的核心服务
Model Hub 托管各种预训练模型,包括 CLIP、BERT、GPT 等。每个模型都有详细的说明和使用示例。
Dataset Hub 托管训练数据集,供研究和开发使用。
Spaces 是在线演示和部署环境,可以快速创建 AI 应用的演示页面。
Inference API 提供在线推理服务,无需下载模型就能使用。
模型文件结构
每个 Hugging Face 模型仓库包含:
config.json- 模型配置文件pytorch_model.bin或model.safetensors- 模型权重tokenizer.json- 分词器(用于处理文本)README.md- 项目说明- Model Card - 模型的详细说明文档
下载模型的三种方式
方式一:Python 代码下载(推荐)
使用 transformers 库,自动下载并缓存到本地:
from transformers import AutoModel
model = AutoModel.from_pretrained('model_name')
方式二:命令行下载
使用 huggingface-cli 或 git clone:
huggingface-cli download model-name --local-dir ./model
方式三:网页下载
直接在模型页面点击 "Files and versions",选择文件下载。适合下载单个文件或小模型。
模型缓存和镜像加速
下载的模型默认缓存在 ~/.cache/huggingface/,重复使用时无需重新下载。如果下载速度慢,可以使用国内镜像加速(如 Hugging Face 官方提供的镜像)。在这个项目中,我们会用到镜像加速来快速下载 CLIP 模型。
Model Card 很重要
每个模型都有一个 Model Card,包含模型介绍、训练数据、性能指标、使用方法和限制说明。使用模型前务必阅读,了解模型的适用场景和限制。
AI、机器学习和大模型
在深入了解 CLIP 之前,我们先理清几个核心概念的关系。
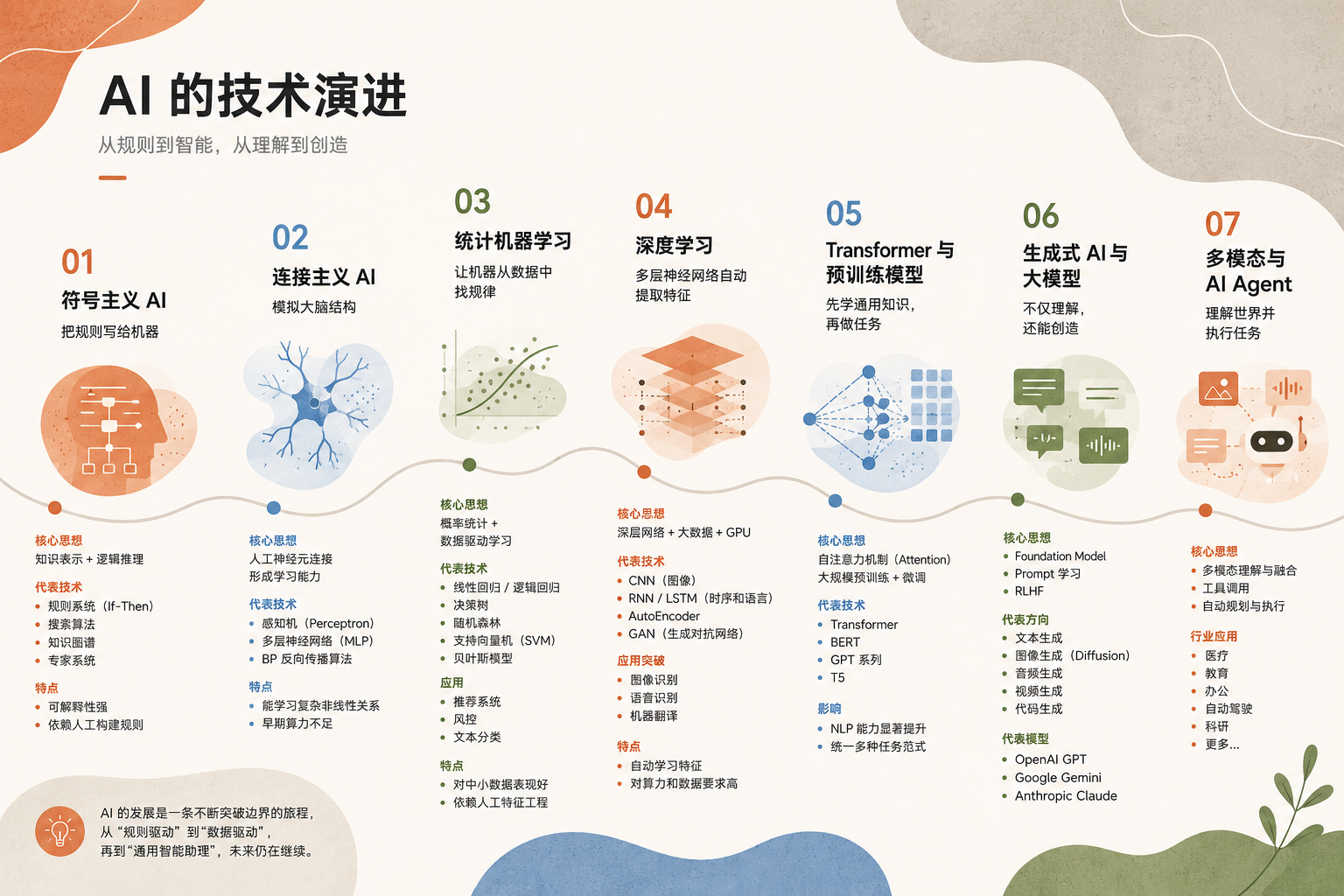
AI 发展历程:从规则系统到深度学习,再到大模型时代
机器学习是 AI 的子集
机器学习(Machine Learning)是人工智能的一个分支,它的核心思想是:让计算机从数据中学习规律,而不是由人工编写所有规则。传统程序需要程序员明确每一条逻辑,而机器学习模型通过训练数据自动"学会"如何处理任务。
深度学习是机器学习的方法
深度学习(Deep Learning)是机器学习的一种方法,使用多层神经网络来学习数据中的复杂模式。深度学习在图像识别、自然语言处理等领域取得了突破性进展,正是因为神经网络能够自动提取特征,无需人工设计。
大模型是深度学习的产物
大模型(Large Models)指的是参数量巨大的深度学习模型。它们的特点是:
- 规模巨大:参数量从几亿到几千亿甚至更多
- 数据量大:训练数据来自互联网的海量文本、图像等
- 能力强:展现出强大的泛化能力,能处理多种任务
- 涌现能力:当模型规模达到一定程度时,会突然出现设计时未曾预料的能力
从机器学习到大模型的演进
机器学习的发展经历了几个阶段:
- 传统机器学习:使用人工设计的特征(如 SIFT、HOG),模型相对简单
- 深度学习:神经网络自动学习特征,性能大幅提升
- 大模型时代:模型规模爆炸式增长,能力从单一任务扩展到通用智能
CLIP 就是这个演进过程中的产物——它是一个大规模多模态模型,通过对比学习在 4 亿对图文数据上训练,实现了图像和文本的统一理解。
CLIP 是什么
CLIP(Contrastive Language-Image Pre-training)是 OpenAI 发布的多模态模型。它能把图片和文字映射到同一个向量空间,实现:
- 用一句话搜索图片(不需要标签)
- 零样本图片分类——没见过猫的类别也能认出猫
- 图文相似度计算
简单说:你给它一张图,再给它几个词(比如「猫」「狗」「汽车」),它会告诉你这张图和哪个词最匹配。不需要训练,开箱即用。
举个🌰
我用 CLIP 对 OpenAI CEO Sam Altman 进行预测,提供了几个有意思的标签,结果也显示他是「骗子」和「企业家」的概率远远高过他是「科技人物」的可能性🤣

Sam Altman 照片
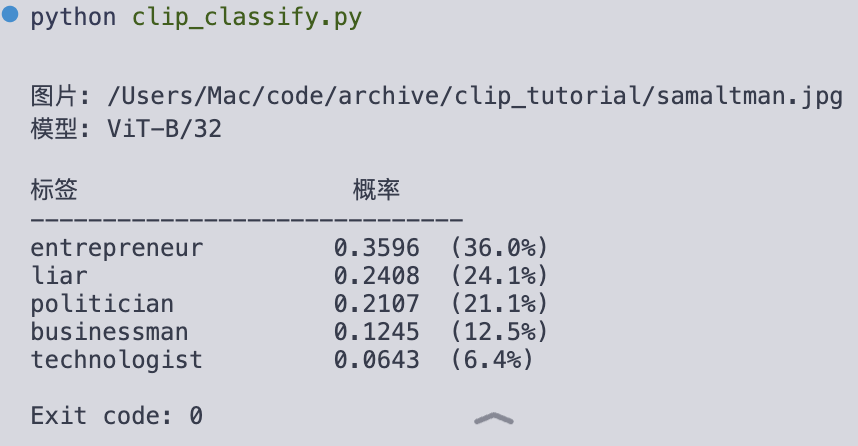
CLIP 预测结果
为什么要 clone 仓库?在科研和实际项目中,很多模型都需要从 GitHub 仓库获取源码。学会这个流程很重要——clone、安装依赖、运行代码。AI 会帮你搞定一切。
环境方案选择
根据你的情况选一种:
| 方案 | 适合谁 | 推荐度 |
|---|---|---|
| 本地 WSL/ubuntu双系统 + AI IDE | Windows 用户,电脑配置还行 | ⭐⭐⭐ 最推荐 |
| 云服务器 + SSH + AI IDE | 电脑配置不够,或想随时随地开发。租 GPU 推荐 CompShare(不推荐 AutoDL) | ⭐⭐ 推荐 |
| Windows 原生 + AI IDE | 不想折腾 WSL | ⭐⭐ 推荐 |
不管你选哪种,操作完全一样:打开终端 → 复制粘贴下面的命令 → 或者直接让 AI 帮你敲。
第一步:克隆仓库并安装依赖
打开合适的目录,对 AI 说:
指令:
「帮我在该目录下 clone https://gitee.com/michaelowenliu/CLIP.git 仓库,然后使用镜像源安装依赖」
第二步:下载模型
对 AI 说:
指令:
「帮我把需要的模型(小一些)下载到本地,存储到一个目录下面,不要下载到缓存里面,使用huggingface镜像加速下载」
第三步:让 AI 写推理脚本
对 AI 说:
指令:
「帮我写一个 Python 脚本,使用 CLIP 仓库的 API 做零样本图片分类。就是加载模型,接收一张图片和几个候选标签,输出每个标签的匹配概率。图片路径和标签写在脚本最上面,方便我修改。」
第四步:运行,看结果
对 AI 说:
指令:
「帮我运行这个脚本,用一张测试图片」
第五步:自己玩
现在换你自己的图片,改几个标签试试。比如:
- 拍一张你的书桌 → 标签:
["书桌", "餐桌", "办公桌", "梳妆台"] - 拍一张校园风景 → 标签:
["校园", "公园", "街道", "森林"] - 拍一张食物 → 标签:
["中餐", "日料", "西餐", "甜点"]
想玩更高级的?对 AI 说:
试试对 AI 说这些:
- 「帮我把脚本改成批量识别一个文件夹里的所有图片」
- 「(如果在本地有AI IDE或者Claude code的话):帮我把这个分类的脚本弄成一个本地网页服务,我可以在网页点击上传图片,同时给候选框我可以自己填标签方便一些」
- 「我想要将CLIP和SAM结合在一起实现目标分割,帮我完成」
- 「解释一下 CLIP 是怎么把图片和文字映射到同一个空间的」
恭喜!你已经跑通了第一个 AI 项目。不需要懂深度学习,不需要看懂模型架构——你只需要知道想要什么,AI 帮你实现。这就是 AI Coding 的核心工作方式。